
WooRank's Site Crawl Will Change How You See Your Site
Here at WooRank, we're always cooking up new ways we can help you improve your website's search rankings and user experience so you can get more out of your marketing efforts. And our latest project is a big one, so we're very excited to announce WooRank's newest tool: Site Crawl!
What Is It?
As you probably know, digital marketing isn't easy, especially when you're focusing on organic search traffic. In fact, there's a chance your site has issues that, while seemingly minor and hidden away on individual pages, could be adding up to real problems for your SEO. That's where Site Crawl comes in.
Site Crawl digs through your pages to find the following issues that could be affecting your site:
- On-page problems
- Duplicate content
- Indexing issues
- Return tag errors
- Canonicalization issues
These issues can represent serious stumbling blocks for search engines. Checking your site and fixing these issues will help search engines crawl and index your pages more effectively, and will help improve your site's performance in search rankings.
How Does It Work?
You can open Site Crawl by either clicking the icon on your account Overview page, on the Site Crawl link at the left side of your Project. To start using the tool, just click "Run the first crawl" and give our spiders time to do their thing (this won't take more than 10 minutes). Note that you can crawl your site once a week to check up on your changes.
We've color coded the information in Site Crawl to help you better categorize and prioritize your work:
- Red: These are high priority, critical issues that are potentially seriously impacting your site's SEO. You should fix these issues right away.
- Orange: These are medium priority issues that are important, but are less critical than issues in red.
- Blue: These are informational notes. They aren't necessarily impacting your site's ranking, but you should still be aware of what's on your site.
The results of your site crawl is broken up into four sections:
- On-Page
- HTTP Status
- Indexing
- Canonical
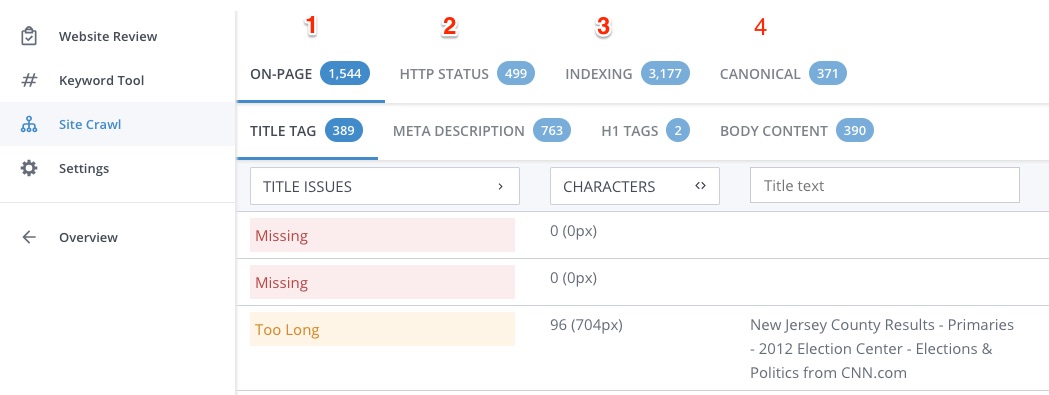
Here's what each of these sections looks at:
1. On-Page SEO
The On-Page SEO section finds problems and errors with your site's HTML and page content. This includes title tags, meta descriptions, H1 tags and thin or duplicate body content. These errors can make it more difficult for search engines to interpret your content, or might make your site look low quality.
- Title Tags: Site Crawl finds pages with missing, too long, too short and duplicate title tags. Titles are cut off in search results after about 65 characters (or 512 pixels), so users won't see keywords that appear at the end of longer titles, while short titles don't make the most out of this important ranking factor. Pages with duplicate title tags are interpreted by search engines as signs of duplicate content.
- Meta Description: This section identifies missing, too long, too short and duplicate meta descriptions on your site. Search engines create their own descriptions when pages have missing, short or inaccurate descriptions, meaning your page's search snippet could be less attractive to click on. Like title tags, every page should have a unique meta description to avoid possible duplicate content issues.
- H1 Tags: This section identifies pages with missing or multiple H1 tags. Search engines see H1 tags as content titles and will struggle to interpret pages without one. Using multiple H1 tags on a page is an old black hat SEO trick to rank for multiple unrelated keywords, so using more than one per page can make your site look like webspam.
- Body content: This section finds pages with thin or duplicate content within the <body> tag. Websites that host a lot of thin (fewer than 250 words) or even blank pages, or include lots of copied text, run the risk of being seen as a low quality site. This will cause a site to struggle to rank for any keywords. Pages that include only video content could include video transcripts in order to provide search engines with content that can be easily crawled.
2. HTTP Status
The HTTP Status section lists pages that return HTTP status codes that indicate issues that could be impairing your site's accessibility, usability and ability to distribute link juice between pages. HTTP error codes frustrate users, who are unable to access the pages they want to visit, and prevent search engines from crawling and indexing pages. If a search engine encounters a lot of HTTP error codes it could result in your page being deindexed.
- 5xx Errors: A server returns a 5xx error code when it is unable to fulfill a request from a browser due to it timing out, the page being inaccessible or the site being busy.
- 4xx Errors: A server returns 4xx codes when it receives an invalid request from the client (browser). Requests can be invalid due to lack of authority to access a page, using an unrecognized request method, bad syntax or the requested page not existing.
- 3xx Redirects: 3xx redirect codes are technically not errors; they instruct the browser to complete an additional step to load the page. However, redirect errors such as redirect loops, redirect chains and broken redirects all negatively affect user experience and SEO.
- HTTP within HTTPS: This section identifies pages hosted on secure URLs that contain assets (images, JavaScript, CSS, etc.) that do not use HTTPS. Security is a ranking signal for Google and important for users, and these non-HTTPS assets make your page less secure.
3. Indexing
The Indexing section identifies pages that might not be fully indexable by search engines, and therefore cannot be displayed in search results. This is often done intentionally, like during a site migration, but can sometimes happen inadvertently, keeping your pages out of search results no matter how high quality or relevant to a search query they might be.
- Non-Indexable Pages: These pages are not being crawled and/or indexed due to their use of noindex X-Robot-Tags, meta robots tags, robots.txt files or canonical tags. This section also identifies whether or not the non-indexable page is included in your XML sitemap.
- Disallowed Pages: These pages are disallowed via your site's robots.txt file. This section also displays whether or not the page is listed in your sitemap.
- Nofollowed Pages: This section lists internal links - links on your pages pointing to other pages on your site - that have the nofollow attribute. The nofollow attribute prevents your pages from passing link juice to the rest of your site, meaning it could be less than fully optimized.
4. Canonical
Canonical tags tell search engines that the page hosts content that is copied, or similar enough to be considered duplicate, from another URL. The URL within the canonical tag tells search engines where they can find the original version of the page, and where they should consolidate link juice. These tags are an important tool in dealing with duplicate content that naturally arises from large and/or complicated websites.
The canonical section identifies problems arising from canonical tags and links on your website:
- Conflicting Canonicals: The URL listed in the canonical tag cannot be accessed.
- Sitemap Mismatch: The URL in the page's canonical tag does not match the URL listed in your sitemap.
- Open Graph Mismatch: The canonical tag URL does not match the site's Open Graph URL.
- Broken Hreflang Issues: A page's hreflang tag contains a URL that links to a broken page.
- Self-Referencing: It's common practice for a canonical URL to include a link to itself. This is a self-referencing canonical tag. You can choose to filter out self-referencing canonical tags for easier analysis.
- Non Self-Referencing: These are pages that include canonical tags that link to another URL. These are the tags you want to pay extra attention to since this is where things can go really wrong if you're not careful.
How Do You Get It?
Using Site Crawl is incredibly easy. There's no setup, no information to enter or outside accounts to sync. It's just a two-step process:
- Click the Site Crawl link on your Overview page or Project
- Click "Run the first crawl" (or "Recrawl site" if you've crawled your site before)
That's all there is to it. It's simple and easy but using Site Crawl to regularly check your site will have powerful results for your SEO. With WooRank's Site Crawl you can quickly and easily find issues with your pages' meta tags, content, server status, canonical URLs and security so you can fix them and get your page back into search results.
Stay Tuned for More
There's always something new on the way here at WooRank as we work to help website owners improve their SEO. Stay up to date on the latest tools and features here on the blog. You'll never miss an opportunity to bring more traffic to your website!

.jpg)







