A robots.txt file is a plain text file that specifies whether or not a crawler should or shouldn 't access specific folders, subfolders or pages, along with other information about your site. The file uses the Robots Exclusion Standard, a protocol set in 1994 for websites to communicate with crawlers and other bots. It 's absolutely essential that you use a plain text file: Creating a robots.txt file using HTML or a word processor will include code that search engine crawlers will ignore if they can 't read.
How Does it Work?
Crawlers are tools that analyse your web pages and can be used to help you identify issues. WooRank's Site Crawl does this to help webmasters find and fix crawl errors.
When a site owner wants to give some guidance to web crawlers, they put their robots.txt file in the root directory of their site, e.g https://www.example.com/robots.txt. Bots that follow this protocol will fetch and read the file before fetching any other file from the site. If the site doesn 't have a robots.txt, the crawler will assume the webmaster didn 't want to give any specific instructions and will go on to crawl the entire site.
Robots.txt is made up of two basic parts: User-agent and directives.
User-Agent
User-agent is the name of the spider being addressed, while the directive lines provide the instructions for that particular user-agent. The User-agent line always goes before the directive lines in each set of directives. A very basic robots.txt looks like this:
User-agent: Googlebot
Disallow: /
These directives instruct the user-agent Googlebot, Google 's web crawler, to stay away from the entire server - it won 't crawl any page on the site. If you want to give instructions to multiple robots, create a set of user-agent and disallow directives for each one.
User-agent: Googlebot
Disallow: /
User-agent: Bingbot
Disallow: /
Now both Google and Bing 's user-agents know to avoid crawling the entire site. If you want to set the same requirement for all robots, you can use what 's called a wildcard, represented with an asterisk (*). So if you want to allow all robots to crawl your entire site, your robots.txt file should look like this:
User-agent: *
Disallow:
It 's worth noting that search engines will choose the most specific user-agent directives they can find. So, for example, say you have four sets of user-agents: One using using a wildcard (*), one for Googlebot, one for Googlebot-News and one for Bingbot, and your site is visited by the Googlebot-Images user-agent. That bot will follow the instructions for Googlebot, as it is the most specific set of directives that apply to it.
The most common search engine user-agents are:
User-Agent Search Engine Field baiduspider Baidu General baiduspider-image Baidu Images baiduspider-mobile Baidu Mobile baiduspider-news Baidu News baiduspider-video Baidu Video bingbot Bing General msnbot Bing General msnbot-media Bing Images & Video adidxbot Bing Ads Googlebot Google General Googlebot-Image Google Images Googlebot-Mobile Google Mobile Googlebot-News Google News Googlebot-Video Google Video Mediapartners-Google Google AdSense AdsBot-Google Google AdWords slurp Yahoo! General yandex Yandex General
Disallow
The second part of robots.txt is the disallow line. This directive tells spiders which pages they aren 't allowed to crawl. You can have multiple disallow lines per set of directives, but only one user-agent.
You don 't have to put any value for the disallow directive; bots will interpret an empty disallow value to mean that you aren 't disallowing anything and will access the entire site. As we mentioned earlier, if you want to deny access to the entire site to a bot (or all bots), use a slash (/).
You can get granular with disallow directives by specifying specific pages, directories, subdirectories and file types. To block crawlers from a specific page, use that page 's relative link in the disallow line:
User-agent: *
Disallow: /directory/page.html
Block access to whole directories the same way:
User-agent: *
Disallow: /folder1/
Disallow: /folder2/
You can also use robots.txt to block bots from crawling certain file types by using a wildcard and file type in the disallow line:
User-agent: *
Disallow: /*.ppt
Disallow: /images/*.jpg
Disallow: /duplicatecontent/copy*.html
While the robots.txt protocol technically doesn't support the use of wildcards, search engine bots are able to recognize and interpret them. So in the directives above, a robot would automatically expand the asterisk to match the path of the filename. For example, it would be able to figure out that www.example.com/presentations/slideshow.ppt and www.example.com/images/example.jpg are disallowed while www.example.com/presentations/slideshowtranscript.html isn 't. The third disallows crawling of any file in the /duplicatecontent/ directory that starts with "copy" and ends in ".html". So these pages are blocked:
- /duplicatecontent/copy.html
- /duplicatecontent/copy1.html
- /duplicatecontent/copy2.html
- /duplicatecontent/copy.html?id=1234
However, it would not disallow any instances of "copy.htm" stored in another directory or subdirectory.
One issue you might encounter with your robots.txt file is that some URLs contain excluded patterns in URLs we would actually want to be crawled. From our earlier example of Disallow: /images/*.jpg, that directory might contain a file called "description-of-.jpg.html". That page would not be crawled because it matches the exclusion pattern. To resolve this, add a dollar symbol ($) to signify that it represents the end of a line. This will tell search engine crawlers to avoid only files that end in the exclusion pattern. So Disallow: /images/*.jpg$ blocks only files that end in ".jpg" while allowing files that include ".jpg" in the title.
Allow
Sometimes you might want to exclude every file in a directory but one. You can do this the hard way by writing a disallow line for every file except the one you want crawled. Or you can use the Allow directive. It works pretty much like you would expect it to: Add the "Allow" line to the group of directives for a user-agent:
User-agent: *
Allow: /folder/subfolder/file.html
Disallow: /folder/subfolder/
Wildcards and pattern-matching rules work the same for the Allow directive as they do for Disallow.
Non-Standard Directives
There are a few other directives you can use in your robots.txt file that aren 't universally recognized by search engines. One is is the Host directive. This is recognized by Yandex, the most popular search engine in Russia, and works as a www resolve. However as it seems Yandex is the only major search engine that supports the Host directive, we don 't recommend using it. The best way to handle the www resolve is using 301 redirects.
Another directive that 's supported by some search engines is crawl-delay. It specifies a numerical value that represents a number of seconds - the crawl-delay line should look like crawl-delay: 15. It 's used differently by Yahoo!, Bing and Yandex. Yahoo! and Bing use the value as a wait time between crawl actions while Yandex will use it as a wait time for accessing your site. If you 've got a big site you probably don 't want to use this directive as it can seriously limit the number of pages that get crawled. However, if you get little to no traffic from those search engines, you can use crawl-delay to save bandwidth.
You can also set the crawl-delay to specific user agents. For example, you may find that your site is frequently crawled by SEO tools, which could slow down your site. You may also wish to block them all together if you don 't feel they are helping you.
Finally, you can use your robots.txt file to tell search engines where to find your sitemap by adding the Sitemap: line anywhere in the file. This directive is independent of user-agent so bots will be able to interpret it wherever you put it, but it 's best to put it at the end to make things easier on yourself. Create a new sitemap line for every sitemap that you have, including your image and video sitemaps or your sitemap index file. If you would rather your sitemap location was not available for all to see, you may prefer to leave this out and instead submit sitemaps to the search engines directly.
Learn more about how to create and optimize your XML sitemap here.
Why Would You Want One?
If getting your site crawled, indexed and ranked in search engine results is the whole point of SEO, why would you ever want to exclude files on your site? There 's a couple of reasons you 'd want to block bot access to areas of your site:
- You 've got private folders, subfolders or files on your site - just keep in mind that anyone can read your robots.txt file, so highlighting the location of a private file using the disallow directive would reveal it to the world.
- By blocking less important pages on your site you prioritize the bots ' crawl budget. This means they 'll spend more time crawling and indexing your most important pages.
- If you get a lot of traffic from other crawlers that aren 't search engines (such as SEO tools), save bandwidth by disallowing their user-agents.
You can also use robots.txt to prevent search engines from indexing duplicate content. If you use URL parameters that result in your site housing the same content across several pages, use wildcards to exclude those URLs:
User-agent: *
Disallow: /*?
This will prevent crawlers from accessing any pages that have question marks in the URL, which is often how parameters are added. This is especially helpful for e-commerce sites that wind up with lots of URL parameters causing a ton of duplicate content due to product filtering and sorting.
It 's best practice to block access to your site while redesigning or migrating, which we covered in detail previously. Block access to your entire new site to avoid having it associated with duplicate content, which will hinder its ability to rank in the future.
Common Problems with Robots.txt and How to Fix Them
To check if you 've got a problem with your robots.txt, open up Google Search Console. Check your Crawl Stats report to see if there 's a big drop off in the number of pages crawled per day; this could indicate a problem with your robots.txt.
Possibly the biggest problem with robots.txt files is accidentally disallowing pages you actually want to get crawled. This information can be found in your GSC Crawl Errors report. Check for pages that return a 500 response code. This is the code often returned for pages blocked by robots.txt.

Check any URLs that return a 500 error code against your disallow directives in the robots.txt file.
Some other common issues with robots.txt files are:
- Accidentally adding forward slashes at the end of file names. Even though your canonical URL might include the trailing slash, adding this to the end of a line in robots.txt will cause bots to interpret it as a directory, not a file, blocking every page in the folder. Double check your disallow lines for trailing slashes that shouldn 't be there.
- Blocking resources like CSS and JavaScript codes using robots.txt. However, this will impact the way search engines will see your page. A while back Google stated that disallowing CSS and Javascript will count against your SEO. Google can read your CSS and JS code and use it to draw conclusions about your site. When it sees blocked resources like this it can 't properly render your page which will keep you from ranking as highly as you could otherwise.
- Using more than one User-agent directive per line. Search engines will disregard directives that include more than one user-agent in a line, which can cause them to improperly crawl your site.
- Improper capitalization of directory, subdirectory and file names. While the actual directives used in robots.txt are not case sensitive, their values are. So Search engines see Disallow: page.html, Disallow: Page.html and Disallow: page.HTML as three separate files. If your robots.txt file includes directives for "Page.html" but your canonical URL is in all lowercase, that page will get crawled.
- Using the noindex directive. Neither Google or Bing support the use of noindex in robots.txt files.
- Contradicting your sitemap in your robots.txt file. This is most likely to happen if you use different tools to create your sitemap and robots.txt files. Contradicting yourself in front of the search engines is always a bad idea. Fortunately this is pretty easy to find and fix. Submit and crawl your sitemap via GSC. It will provide you with a list of errors that you can then check against your robots.txt file to see if you 've excluded it there.

- Disallowing pages in your robots.txt file that use the noindex meta tag. Crawlers blocked from accessing the page won 't be able to see the noindex tag, which can cause your page to appear in search results if it 's linked to from another page.
It 's also common to struggle with the robots.txt syntax, especially if you don 't have much of a technical background. One solution is to have someone who is familiar with the robots protocol to go over your file for syntax errors. Your other, and probably better option, is to go right to Google for testing. Open the tester in Google Search Console and paste in your robots.txt file and hit Test. What 's really handy here is that not only will it find errors in your file, but you can also see if you 're disallowing pages that Google has indexed.
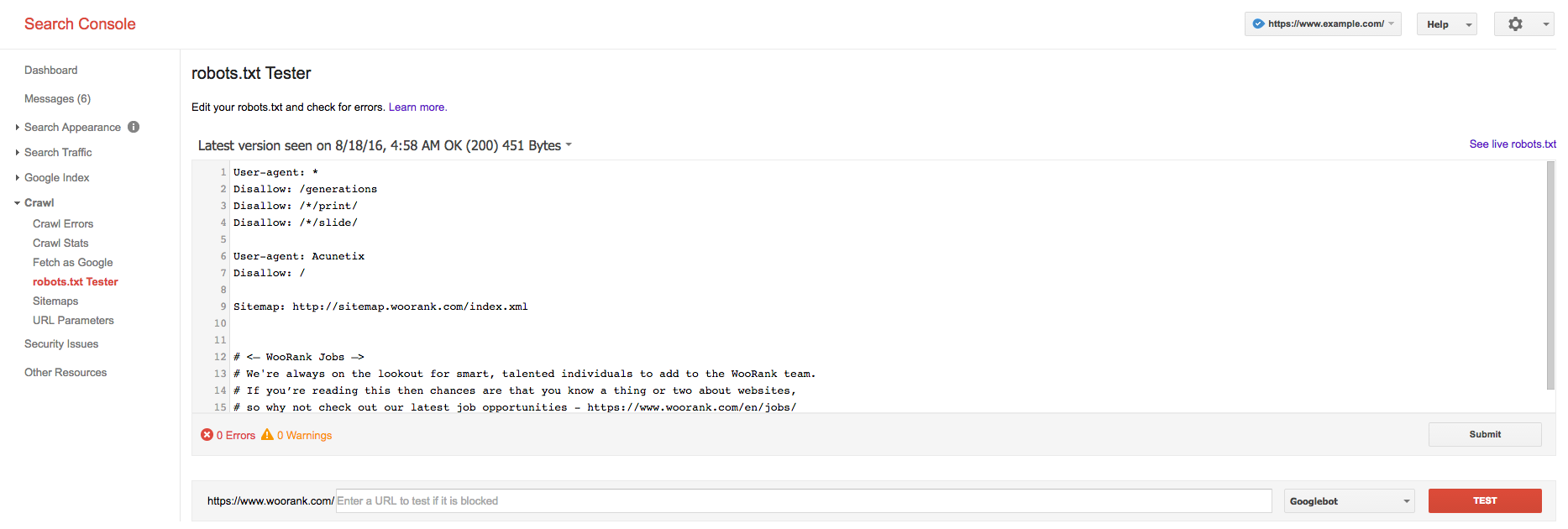
When creating or changing your robots.txt file you really must test it thoroughly using this tool. Adding a robots.txt file that has errors will likely seriously impact your site 's ability to get crawled and indexed, which can cause it to fall out of the search rankings. You could even wind up blocking your entire site from appearing in search results!
Is your robots.txt file properly implemented? Audit your site using WooRank to make sure you 're optimized across 70+ criteria including on page, technical and local factors.





