Ranking at the top of search results all starts with making sure Google can crawl and index your content. When it can't properly open a page or move from one page to another, it's unable to index the content. These instances are known as crawl errors.
In this article, you'll learn:
What is a Crawl Error?
Crawl errors are issues encountered by search engines as they try to access your pages. These errors prevent search engine bots from reading your content and indexing your pages.
Crawl Errors can also refer to a report available in the legacy version of Google Search Console.
The Crawl Errors report has two main sections:
- Site errors: These errors prevent Googlebot from accessing your entire website.
- URL errors: These errors occur when Googlebot is unable to access a specific URL.
In the new Google Search Console, these errors are reported on a URL-by-URL basis in the Index Coverage report.

The new Search Console Index Coverage section also tracks indexing over time, displaying how many...
- Errors they 've encountered (and how many you 've resolved)
- Valid pages Google has indexed
- Pages Google has encountered but not indexed
- Valid pages Google has indexed but found some errors on
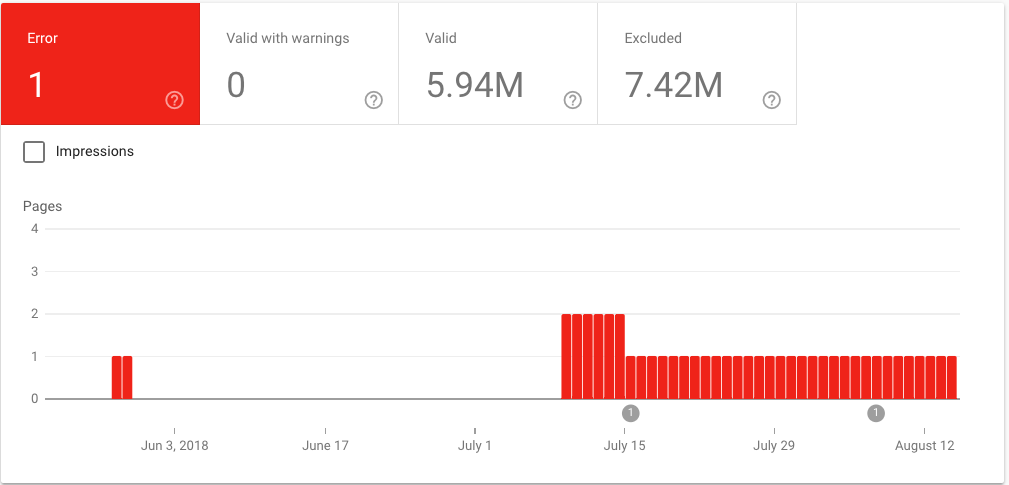
For the purposes of covering crawl errors, we 'll only discuss the Errors section, as these issues are what will keep your pages from being crawled or indexed by Google.
Site errors
Site errors are problems that occur at a site level. Site errors mean that your users and Google are unable to access any of your pages.
So don 't skip these errors.
There are 3 site errors Google counts as crawl errors.
DNS Error
A DNS, which stands for "domain name system", translates a website 's IP address from a string of numbers into usable letters and numbers. Essentially, it 's what allows us to navigate the internet without having to know the IP address of every website you want to visit.
The DNS system works like this:
- You type a domain name into your browser.
- The browser checks to see if the information for that domain is stored locally on your computer.
- If it 's not, the browser sends a request to your local DNS server (usually provided by your ISP).
- The local DNS server looks for the domain name 's details. If it doesn 't have any information, it needs to find the domain 's root name server.
- To find the server, the DNS server will break the URL up into chunks, going from right to left. So for www.example.com, it breaks the URL up into "com", "example" and "www".
- The DNS server connects to the DNS root name server to learn the location of the server for the first chunk of the domain: ".com". This is known as the top-level domain (TLD) name server.
- The DNS server connects to the TLD server.
- The DNS server will ask the TLD name server for details about the name server containing details about the domain name ("example" in our case).
- At this point, the DNS server asks the name server for the information about example.com and the name server returns with the IP address for the domain.

Making a DNS connection is vital since it 's the very first step in accessing a website. If Google can 't establish a DNS connection, it can 't find, much less access, your website.
There are 2 types of DNS errors Google encounters:
- DNS timeout: Your DNS server didn 't respond to Google 's request fast enough.
- DNS lookup: Google wasn 't able to access your website because your DNS server couldn 't find your domain name.
If you 're not able to fetch your site as Google using their tool, check with your DNS provider.
Server Errors
Server errors are different from DNS errors. They mean that Google was able to look up your URL on the DNS server. However, it can 't load the page because of a server issue.
This usually means that your server is taking too long to respond and Google 's request has timed out. Google will dedicate only a certain amount of time to waiting for a server response. Take too long and the bot will give up.
Like DNS errors, a server error is a big deal for your website. It means that something has gone wrong with your server that is preventing users and bots from accessing your website.
How you fix your server error will depend on what the error is. There are several types of server errors:
- Timeout: The server simply took too long to respond to Googlebot 's request.
- Truncated headers: Your server closed its connection before full headers were sent.
- Connection reset: Google was able to connect to your site, but didn 't receive anything because the connection was reset mid-response.
- Truncated response: The connection was ended before Google received a full response.
- Connection refused: Your server refused to connect with Googlebot.
- Connect failed: Your server 's network was down or unreachable.
- Connect timeout: The connection took too to process.
- No response: The connection with your server was ended before any response could be sent.
Check out Google 's help article for resources on how to troubleshoot each type of server error.
Robots failure
Robot failures refer to Google 's inability to find and read a website 's robots.txt file at www.yoursite.com/robots.txt. If DNS is step 1 and making a server connection is step 2, then reading robots.txt is step 3 in Google crawling a website.
Google doesn 't want to crawl and index any pages you don 't want it to, so if it 's unable to access a robots.txt file it knows is there, it will postpone crawling until it 's able to read the file. Although, if you do want Google to crawl every page on your site, you can forgo adding this file to your domain and ignore this error.
If you see this error in Google Search Console, check how you 've set up your robots.txt file.
- Did you create it as a plain text file?
- Have you disallowed your homepage?
- Does your robots.txt file return a 200 status, or a 404 error?
- Have you double, triple and quadruple checked for a Disallow: / line?
When you encounter a robots error, it 's worth noting that having no robots.txt file is better than having an improperly configured one, since a broken robots.txt file will cause Google to avoid crawling your site altogether.
URL errors
URL errors differ from site errors in that they only apply to the specific page, not your site overall. They note the instances in which Google requested a specific page, but was unable to read it.
Soft 404s
The name "soft 404" can be a bit misleading for some. These aren 't pages that return a 404 status code. In fact, these are pages that return a 200 HTTP status. The problem is, they 're mostly empty pages.
Google is pretty good at finding where content is located on a page. So when a URL contains a page that doesn 't have much or any "main content", it calls that a soft 404. Technically the page exists and returns a 200 status, but it 's an empty page.
Google notes these pages because they 're not very useful for users, they make Googlebot work for no reason and they reduce the efficiency of your site 's crawl.
Your best bet is to either add content to these pages to make them useful or noindex them so Google no longer sees them.
Note that if you use a custom 404 page that doesn 't return a 404 status, it will probably be noted by Google as a soft 404.
Not found
Not found URLs are the actual 404 errors encountered on a website. Google has requested a URL on your site that doesn 't exist.
While seeing lots of "not found" URLs in your Crawl Errors report might make your stomach drop, it 's not as disastrous as it looks.
In fact, according to Google itself, 404 errors do not impact your site 's indexing or ranking.
The vast majority of 404 errors you 'll see won 't need to be fixed. When deciding whether or not to fix a 404 URL, consider:
- Does the URL have a lot of high-quality external links?
- Does it receive a lot of traffic?
- Is it a URL that users/linkers obviously would expect to exist?
If the answer to one or more of these questions is yes, you should probably dig into the cause of the error. If the 404 is caused by faulty internal linking you should definitely fix it.
Fixing your 404s will depend on the cause. It could be as simple as fixing typos in an internal link. If the case of external links to old pages, use a 301 redirect to point it to a new one. If it looks like a URL people would expect to exist on your site, consider adding the page or redirecting to the relevant content elsewhere on your site.
Access denied
These errors happen when Google isn 't allowed to access a certain page. They are typically caused by:
- Password protecting the page
- Pages being disallowed by robots.txt
- Your hosting provider blocking Googlebot (it can happen!)
If you don 't want the URLs listed in this area of Crawl Errors to appear in search results, you don 't need to do anything here. This is actually confirmation that something 's right.
However, if you do want these pages to appear in search results, you 'll have to fix what 's blocking Google.
- Remove the login requirement from the page
- Remove the URL from your robots.txt file.
- Contact your hosting provider to whitelist Googlebot
Not followed
Don 't confuse this error with the link directive or meta robots tag. These URLs have nothing to do with those. Not followed URLs in Crawl Errors are simply URLs that Google couldn 't completely follow to their destination.
Reasons for this could be
- Flash, JavaScript or other active content blocking Google
- Broken redirects, loops or chains
- Relative linking in redirects
- Redirected URLs included in your sitemap
Again, as with 404s and access denied, decide whether not the URLs here are worth fixing. If the pages don 't really matter to your website, you might decide not to worry about fixing them.
Server errors and DNS errors
These are the same types of errors encountered in the site errors above. Google was either unable to find a URL 's DNS, or something went wrong with your server trying to serve the page. The difference here is that these errors are limited to the individual URLs listed, instead of impacting your entire site.
For more guidance from Google on what each error means and how to fix them, read their Google Search Console Help article on Crawl Errors.
URL Inspection Tool
Google Search Console allows you to look up individual pages on your website for indexing issues and crawl errors. You can access the URL inspection for individual URLs 3 ways:
- Clicking the URL inspection link on the left-hand navigation or entering the URL in the search bar at the top of the page after you select a property from the Search Console welcome page.
- Clicking the magnifying glass icon on a URL 's row in the Performance report.
- By
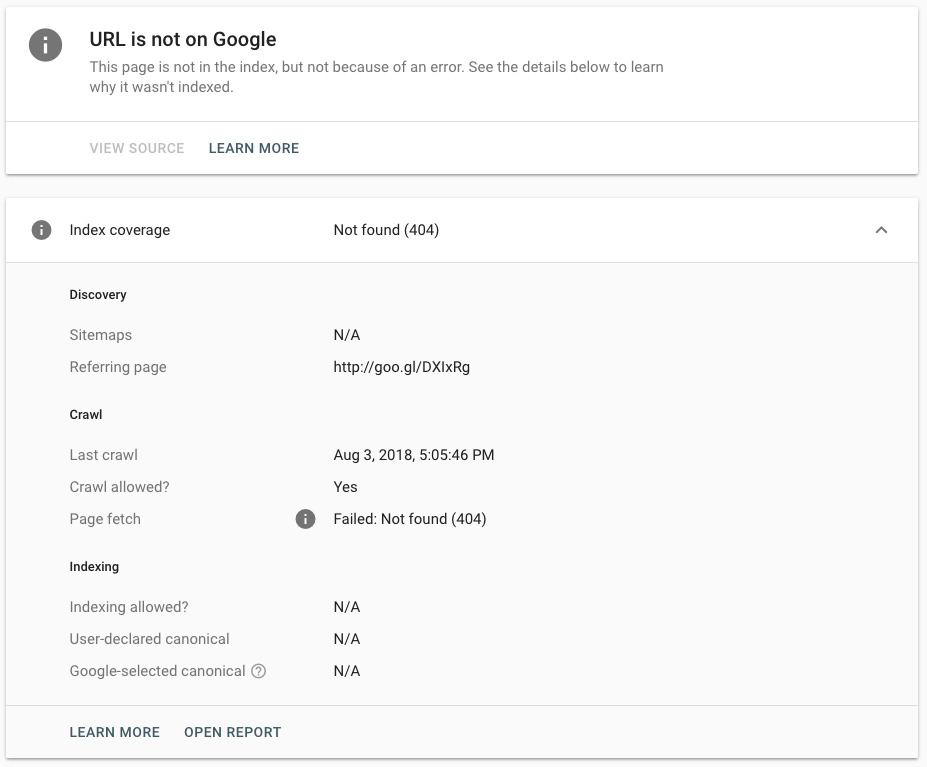
The tool tells you whether or not a page is in Google 's index and details what Google encountered when it tried to call the page.
- The page on which Google found the link to your page.
- The last time Google 's crawlers tried to access the page
Here 's what the tool 's report includes for a page that returns a 404 HTTP status:
What 's the Problem with Crawl Errors?
The most obvious problem with having crawl errors on your site is that these errors prevent Google from accessing your content. Google can 't rank the pages they can 't access. A high rate of crawl errors can also impact the way Google views your website.
A lot of crawl errors can have an impact on how Google views the health of your website overall as well. When Google 's crawlers have lots of problems accessing a site 's content, they can decide that these pages aren 't worth crawling very often. This will lead to your new pages taking a lot longer getting into the Google index than they otherwise would.
Check out WooRank's Site Crawl to find and fix additional crawl errors on your site!





